Ein einzelnes Neuron wird bei der technischen Realisierung auf seine
grundlegenden Funktionen zur Signal-Verarbeitung reduziert.
Bereits mit einem ganz einfach angelegten künstlichen neuronalen Netz lässt sich
die parallele Verarbeitung von Informationen simulieren. Entscheidend
ist, dass "Neuronale Netze" lernen können.
|
|
|
|
Skizze
einer Zeitleiste
|
|
|
|
1951
|
|
Marvin
Minsky und Dean Edmonds entwickelten den ersten auf künstlichen
neuronalen Netzen basierenden Computer. |
|
1958
|
|
Es
entstand das erste komplette auf künstlicher Intelligenz basierende
Software-System: der Advice Taker von Jaohn McCarthy |
|
1970
|
|
Entwicklung
von Expertensystemen. Bekannt wurd das System MYCIN, das der Diagnose
von Blutinfektionen diente. |
|
Mitte
1980er
|
|
Neben
der wieder intensiveren Forschung an künstlichen neuronalen Netzen
entstanden in dieser Zeit auch andere auf klassischer Statistik und
sog. Bayes´schen Netzen basierende automatische Lernverfahren. |
|
|
|
| |
|
Konstruktion eines einfachen neuronalen Netzes |
| |
|
|
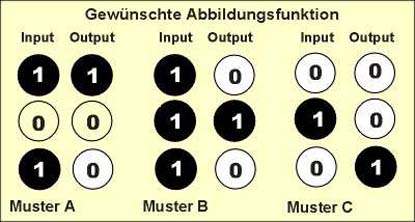
Ein einfaches Abbildungsbeispiel:
Die drei Muster A, B und C sollen erkannt werden und eine je spezifische Reaktion zur Folge haben. Wenn das Muster A erkannt wird, so soll Outputneuron 1 "aktiv" sein, wenn Muster B erkannt wird, so soll Outputneuron 2 "aktiv" sein und entsprechend soll Outputneuron 3 "aktiv" sein, wenn das Muster C erkannt wird. |
|
 |
| |
|
Mathematisch handelt es sich um eine Abbildungsfunktion,
die sich auch vektoriell wie folgt schreiben lässt:
(101) --> (100), (111) --> (010), (010) --> (001) |
|
|
|
|
Lösung
des Abbildungsproblems mit Hilfe eines Programms
in einer seriellen Schrittfolge
|
|
Ein
seriell arbeitender Computer, etwa ein PC, würde das Problem mit folgendem
Programm lösen:
Gehe zum mittleren Input-Neuron und stelle fest, ob es feuert oder nicht;
feuert es nicht, so handelt es sich um Muster A, feuert es, so gehe
zum oberen Input-Neuron; feuert dies nicht, so handelt es sich um Muster
C; feuert es, liegt Muster B vor.
Dies ist noch ein einfaches Programm mit Rechen- und Zuordnungsregeln.
Mit jedem zusätzlichen Abbildungspunkt wird das Programm aber exponentiell
komplizierter. |
| |
|
|
|
Lösung
des Abbildungsproblems mit Hilfe eines einfachen
Neuronalen Netzes
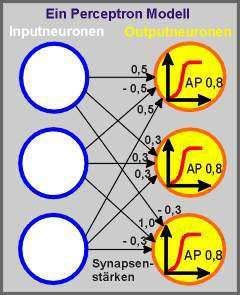
In
einem Perception Modell ist jedes Neuron der Inputschicht mit jedem
Neuron der Outputschicht verbunden. Jeder einzelne Input wird gewichtet
und gelangt so in die Outputschicht. Annahme: Alle drei Outputneuronen
haben ein Aktivierungspotential von 0,8.
(vergleiche hierzu in einem Biologiebuch auch die
Funktion biologischer Neuronen)
|
|
 |
| .. |
|
|
|
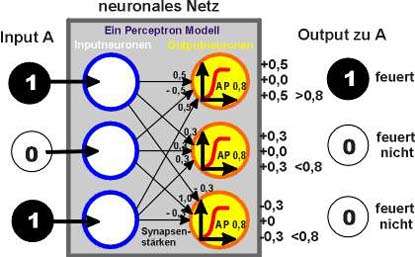
Beispielrechnung
für die Abbildung von Muster A
Wird
Muster A wahr-genommen, entspricht die Aktivität der Inputschicht
diesem Muster.
Über die Verbindungen erhalten alle Neuronen der Outputschicht - mit
unterschiedlichen Synapsen- Stärken gewichtet - diesen Input.
|
|
 |
| |
|
Das obere Neuron der Output- Schicht erhält über seine Synapsen den Gesamt-Input 1. Er ist größer als das AP von 0,8, also feuert das oberste Output- Neuron. Der entsprechend berechnete gewichtete Input des mittleren Neurons beträgt 0,6 der des unteren Neurons -0,6.
Also sind diese beiden Neuronen nicht aktiv. |
| |
|
|
Ein
neuronales Netz verarbeitet alle eingehenden Inputs parallel
und das hat gegenüber der seriellen Ab-Arbeit in Programmen wesentliche
Vorteile!
|
|
Die Verarbeitung
aller Inputs erfolgt parallel: gleichzeitig in allen drei Neuronen
der Outputschicht. Diese Parallelverarbeitung hat wesentliche Vorteile
gegenüber der seriellen Arbeit. So erfolgt das Erkennen des Musters
in einem einzigen Schritt. Besteht also das Muster aus mehr als drei
Bildpunkten, bleibt die Schnelligkeit erhalten. Das Erkennen komplexerer
Muster erfordert also lediglich mehr Neuronen. Das Wissen über die
richtige Zuordnung oder Abbildung steckt im Netz, also erstens in
der Art der Vernetzung der Neuronen, zweitens insbesondere in der
Stärke der Synapsen und drittens im Aktionpotential.
Wenn wir
davon ausgehen, dass unser Gehirn eher wie ein neuronales Netz funktioniert
- und nicht seriell wie ein herkömmlicher Computer arbeitet -
dann erscheinen geistige Prozesse in einem neuen Licht. Ebenso wird
deutlicher, was damit gemeint ist, wenn gesagt wird: das wurde in
der biologischen Evolution gelernt. |
|
|
|
| |
|
Training von Netzwerken - Backpropagation |
| |
|
|
| Ein geschichtliches Beispiel aus dem Jahr 1986
für das Training eines Neuronalen Netzes

Hugo
de Garis bezeichnet sich als "Brain Builder". Seine Maschinen-Katze soll nächstes
Jahr durch die Flure des ATR-Laboratoriums in Kyoto, Japan, laufen. |
|
Vor
knapp zehn Jahren wurde die Theorie neuronaler Netzwerke erstmals auf
das Problem der Bildung der Vergangenheitsform angewandt (Rumelhart & McClelland 1986). Es wurde ein Netzwerk mit 460 Input- und 460
Outputneuronen nach dem Perceptron Modell gebildet (das sind 211600
Verbindungen). Als Inputmuster wurden 420 Wortstämme verwendet,
denen vom Netzwerk 420 Vergangenheitsformen zuzuordnen waren. Sowohl
die Wortstämme als auch die Vergangenheitsformen wurden dem Netzwerk
klanglich dargeboten. Zunächst gab es eine zufällige Aktivierung
der Outputneuronen. Das Aktivierungsmuster der Outputschicht wurde dann
aber mit dem gewünschten Output verglichen und der Fehler zur Neueinstellung
der Synapsengewichte verwendet (Backpropagation-Regel).
Eine Darstellung sprengt aber den Rahmen dieser Arbeitsumgebung. Wichtig
ist, das zwischen Input- und Outputschicht eine dritte Neuronenschicht
eingeführt wird. Das Netzwerk ist dreischichtig.
Die Outputschicht lernte auf diese Weise die korrekte Zuordnung von
Vergangenheitsformen zu einem Wortstamm. Nach insgesamt 79 900 Durchgängen
hatte das Netzwerk die Zuordnung gelernt.
Auch dann, wenn nun neue Verben dargeboten wurden, arbeitete das Netzwerk
noch nahezu fehlerfrei und generierte die Vergangenheitsform von regelmäßigen
Verben mit einer Genauigkeit von 92%. |
| |
|
|
|
Ein
Netzwerk wird trainiert und nicht programmiert
|
|
Das
Neuronale Netz leistet seine Aufgabe, weil die Verbindungstärken
zwischen Hunderten von Neuronen optimal eingestellt sind und nicht,
weil es irgendwelchen seriellen Programmregeln folgt. Ein Netzwerk
wird also trainiert und nicht seriell programmiert. Netzwerke mit
Zwischenschichten sind aus prinzipiellen Gründen in der Lage,
Probleme zu lösen, die zweischichtige Neuronale Netze nicht lösen
können. Sie sind zu Abstraktionsleistungen und Prototypenbildungen
(Generalisierungen) in der Lage.
Beim Training
von Netzwerken unterscheidet man selbstorganisierendes Lernen (das
also ohne äußeren Trainer stattfindet) und angeleitetes
Lernen. Beim ersteren Verfahren führen Systemeigenschaften des
Netzwerkes sowie Regelmäßigkeiten der Eingangssignale zu
spontanem Lernen. Das zweite Verfahren gleicht dem zuvor beschriebenen. |
|
|
|
| |
|
Hoppfield Netzwerke - Künstliche Intelligenz - Mustererkennung und Lernen |
| |
|
|
Ein Hopfield Netzwerk ist ein sich selbstorganisierendes, neuronales
Netz, welches wie bei der Backpropagation lernt. |
|
Hopfield
Netze werden insbesondere bei der Mustererkennung (Sprache und Gesichter)
eingesetzt. Bei
diesen Netzen geht es darum, das Gewichtungen gefunden werden, die
dafür sorgen, dass topologische Strukturen erhalten bleiben. Die Lernregel
legt hier nicht mehr die Multiplikation der Gewichtungen zugrunde,
sondern die Subtraktion. |
| |
|
|
 |
|
Eine
Steigerung der Lernfähigkeit des Homo sapiens sapiens in Synergie
zur Lernfähigkeit künstlich-neuronaler Systeme scheint möglich zu
werden.
Die Informations-
und Biotechnologien wachsen zusammen. Das zeigen die schon heute möglichen
Anwendungen. In technisch "Neuronalen Netzen" werden Computerarchitekturen
konstruiert, die zwar nicht ein biologisches Gehirn nachbilden wollen,
wohl aber die Erkenntnisse der Hirnforschung z. B. die hohe komplexe
Verflechtung und Selbstorganisation als Prinzipien.
Natürlich
gibt es auch Ideen dazu, die Lernfähigkeit des Homo sapiens sapiens
durch Implantation von "künstlicher Intelligenz" zu steigern. |











